之前用 Golang 开发了一个服务器端批量生成大赛获奖证书图片的功能。参考前文(Golang 批量生成获奖证书图片时的字体问题汇总)
然后,不出所料,上线后就被用户反馈有 Bug。哎,做个好人真难,干得越多,出 Bug 越多。
Bug 现象
- 生成的证书图片,涉及到数字下标的一律不显示。例如二氧化碳的下标 2 就不见了,CO₂ 显示成 CO 😅
- 有些字缺笔画。例如,飘逸的逸字,缺少了兔子的点。那个字我就不认识了。
- 有些中文简体字显示成了繁体字
Bug 分析
第一个问题,我还能理解,可能字符支持的不全;但是第二个我就不能理解了。
后来,我看了一下思源字体的属性
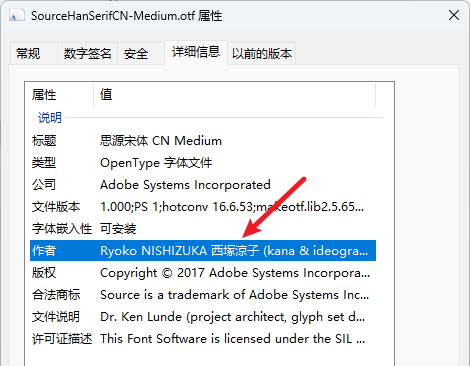
可以看到,作者是日本人,这就解释了为什么有些字缺笔画,有些中文简体字显示成了繁体字。
因为作者不是中国人,所以对简体中文的校验和支持不够全面。
而且,这些外企搞的字体或者软件,早期都是中国台湾地区,或者日本做的测试,其实也看不出什么问题。
理论上,换成一个通用的简体中文字体就能解决。
更换字体
经同事设计大师的推荐,我决定使用阿里巴巴普惠体 3.0 版本的字体。可以免费从官方网站下载:
https://www.alibabafonts.com/#/font
也没有什么版权问题,直接下载使用就行了。
在 Golang 代码中,修改了字体文件后,运行测试,发现之前反馈的 Bug 都解决了。😄
又是惊心动魄的一天。
支持的字符数对比
修复这个 bug 之后,我就无心工作了。可能修复线上问题的精神压力过大,我就想看看不同字体支持的字符数对比,顺便放松一下心情。
于是,让 AI 写了一段 Python 代码,来统计不同字体文件中 cmap 表中的字符数,并打印出来,按照支持的字符数量多少排序。
import os
from fontTools.ttLib import TTFont
def get_supported_chars(font_path):
try:
font = TTFont(font_path)
cmap = font['cmap']
chars = set()
for table in cmap.tables:
chars.update(table.cmap.keys())
return chars
except Exception:
return set()
def list_fonts_char_count(directory='.'):
font_files = [f for f in os.listdir(directory) if f.lower().endswith(('.ttf', '.otf'))]
font_char_counts = []
for font_file in font_files:
chars = get_supported_chars(os.path.join(directory, font_file))
font_char_counts.append((font_file, len(chars)))
font_char_counts.sort(key=lambda x: x[1], reverse=True)
for font_file, count in font_char_counts:
print(f"{count}: {font_file}")
if __name__ == "__main__":
directory = os.path.dirname(__file__) or "."
list_fonts_char_count(directory)
以下是运行结果:
44812: SourceHanSans-Medium.ttf 思源黑体
30847: SourceHanSerifCN-Bold.otf 思源宋体
30847: SourceHanSerifCN-ExtraLight.otf
30847: SourceHanSerifCN-Heavy.otf
30847: SourceHanSerifCN-Light.otf
30847: SourceHanSerifCN-Medium.otf
30847: SourceHanSerifCN-Regular.otf
30847: SourceHanSerifCN-SemiBold.otf
30789: NotoSansHans-Medium.otf
29197: AlibabaPuHuiTi-3-65-Medium.ttf 阿里巴巴字体
但是为何 AlibabaPuHuiTi-3-65-Medium.ttf 支持的字符最少,但是实际使用时,支持的中文字符确实最完整的呢?
原来字体文件中 cmap 表中的字符数只能反映字体声明支持的字符编码(即有字形的码位),但实际显示效果还受以下因素影响:
- 合成字形(合字):有些字体通过合成、替换等方式支持更多字符,但 cmap 只统计基础码位。
- 字体 fallback:操作系统或应用可能自动用其他字体补全缺失字形,导致实际显示比单一字体更完整。
- 字体子集:有些字体文件只包含常用字符,但通过字体家族或外部机制补全。
- 字体文件结构:部分字体可能将多个字符映射到同一个字形(glyph),但 cmap 只统计码位,不统计视觉效果。
- 编码方式:部分字体可能支持某些字符的变体或扩展区,但 cmap 只统计标准区。
cmap 表只能反映“声明支持”的字符数,不能完全代表“实际可用的中文字符覆盖率”。
实际使用时,字体设计、系统渲染和应用 fallback 机制都会影响最终效果。
从阿里巴巴普惠体 3.0 的官网看,显示支持的汉字字符数 87887 个,远远大于 cmap 表中显示的 29197 个字符。

字体文件大小对比
> ls -lah
total 124M
8.1M Jul 29 17:21 AlibabaPuHuiTi-3-65-Medium.ttf* 阿里巴巴字体
8.1M Jul 11 2014 NotoSansHans-Medium.otf* 思源黑体
33M Dec 1 2020 SourceHanSans-Medium.ttf* 思源黑体
12M Jul 25 15:56 SourceHanSerifCN-Bold.otf* 思源宋体
9.9M Jul 25 15:56 SourceHanSerifCN-ExtraLight.otf*
11M Jul 25 15:56 SourceHanSerifCN-Heavy.otf*
11M Jul 25 15:56 SourceHanSerifCN-Light.otf*
11M Jul 25 15:56 SourceHanSerifCN-Medium.otf*
11M Jul 25 15:56 SourceHanSerifCN-Regular.otf*
11M Jul 25 15:56 SourceHanSerifCN-SemiBold.otf*
总结
字体的选择很重要,尤其是中文字体。选择国内大厂的字体更靠谱。
关于作者 🌱
我是来自山东烟台的一名开发者,有感兴趣的话题,或者软件开发需求,欢迎加微信 zhongwei 聊聊,或者关注我的个人公众号“大象工具”, 查看更多联系方式