之前尝试了 Google Gemma 3n 模型,参考笔记 Ollama 安装 Google Gemma 3n 模型。但是,我想找一个占用内存更小,更流畅的 LLM 模型。
恰好看到有人在讨论 qwen3 0.6b 模型,于是测试了一下,发现运行很流畅。
安装并运行
ollama run qwen3:0.6b
测试运行效果
很流畅,居然还带 thinking 过程。。。
模型文件大小
> ollama list
NAME ID SIZE MODIFIED
qwen3:0.6b 7df6b6e09427 522 MB 4 hours ago
gemma3n:latest 15cb39fd9394 7.5 GB 2 weeks ago
相比 gemma3n 这个模型小多了,只有 500M。
内存和 CPU 占用
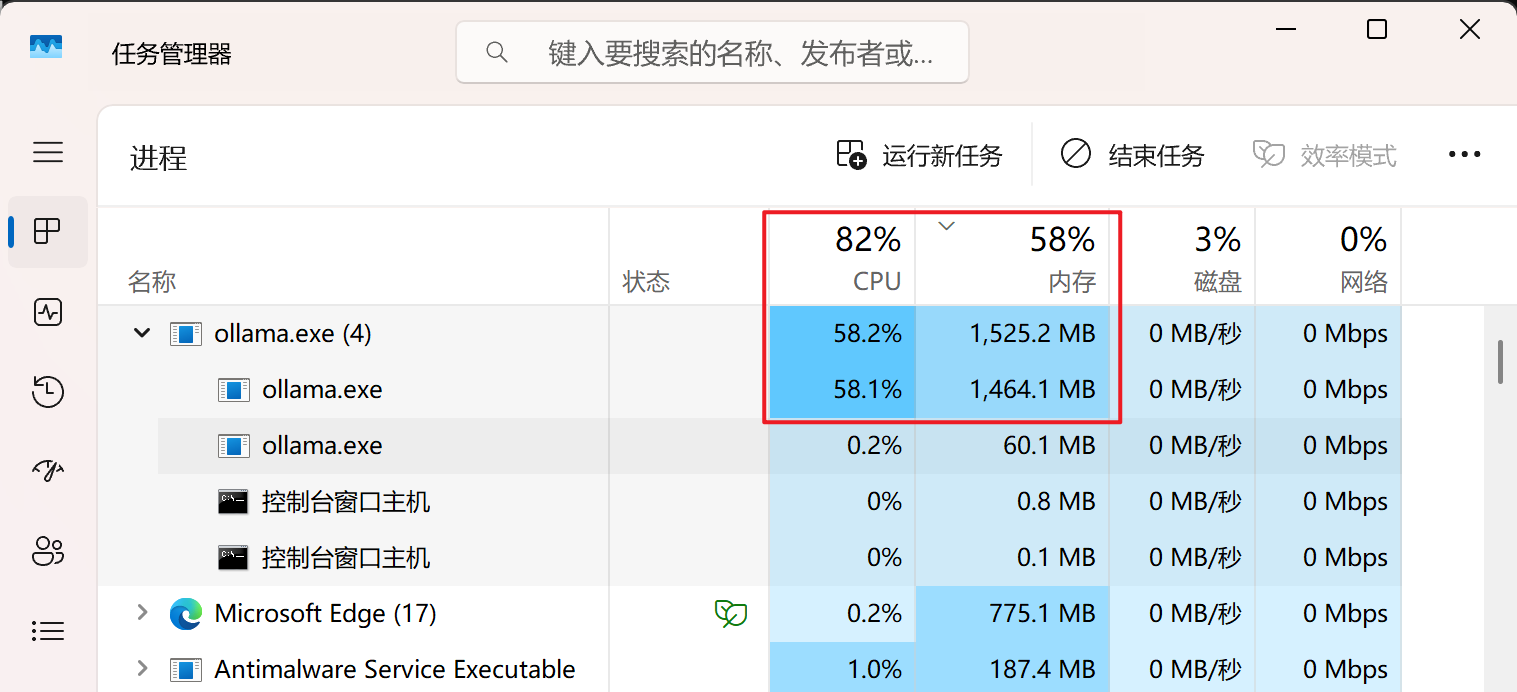
占用内存 1.5G 内存左右。这个就非常完美了。
模型参数
>>> /show info
Model
architecture qwen3
parameters 751.63M
context length 40960
embedding length 1024
quantization Q4_K_M
关于作者 🌱
我是来自山东烟台的一名开发者,有感兴趣的话题,或者软件开发需求,欢迎加微信 zhongwei 聊聊,或者关注我的个人公众号“大象工具”, 查看更多联系方式